The MVAPICH2-DPU MPI library is a derivative of the MVAPICH2 MPI library and is optimized to harness the full potential of NVIDIA Bluefield Data Processing Units (DPUs) with InfiniBand networking and accelerate HPC applications.
Features
The MVAPICH2-DPU 2024.04 release has the following features:
- Based on MVAPICH2 2.3.7, conforming to the MPI 3.1 standard
- Supports all features available with the MVAPICH2 2.3.7 release
- Novel frameworks to offload nonblocking collectives to DPU
- Offloads nonblocking Alltoall (MPI_Ialltoall) to DPU
- Offloads nonblocking Alltoallv (MPI_Ialltoallv) to DPU
- Offloads nonblocking broadcast (MPI_Ibcast)
- Offloads blocking send and receive (MPI_Send, MPI_Recv)
- Offloads noblocking send and receive (MPI_Isend, MPI_Irecv)
- Supports sub-communicator non-blocking collective offloading
- Supports multiple outstanding non-blocking collective operations per MPI rank offloading
- Optimized support for both Intel CPU-based and AMD CPU-based clusters with DPUs, respectively
- Up to 99% overlap of communication and computation with non-blocking collectives
- Accelerates scientific applications using any mox of MPI_Ialltoall, MPI_Ialltoallv, MPI_Ibcast, MPI_Isend, MPI_Irecv nonblocking collective and point-to-point communications
Performance
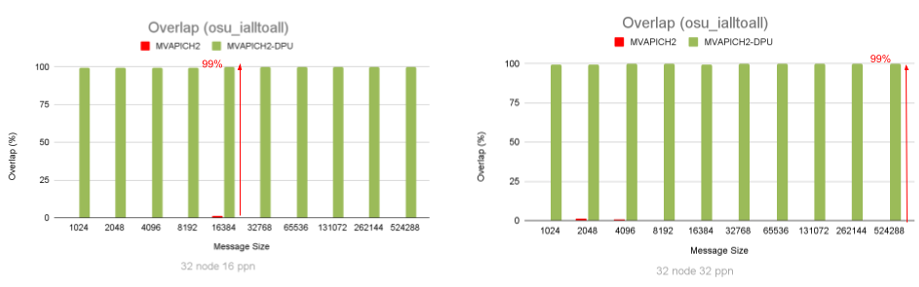
Figure 1: Capability of the MVAPICH2-DPU library to extract peak overlap between computation happening at the host and MPI_Ialltoall communication
Figure 1 illustrates the overlap effect of the MPI_Ialltoall nonblocking collective benchmark running with 512 (32 nodes with 16 processes per node (PPN) each) and 1,024 (32 nodes with 32 PPN each) MPI processes, respectively. As message size increases, the MVAPICH2-DPU library is able to demonstrate peak (99%) overlap between computation and MPI_Ialltoall nonblocking collective. In contrast, the MVAPICH2 default library without such DPU offloading capability is able to provide very little overlap between computation and MPI_Ialltoall nonblocking collective.
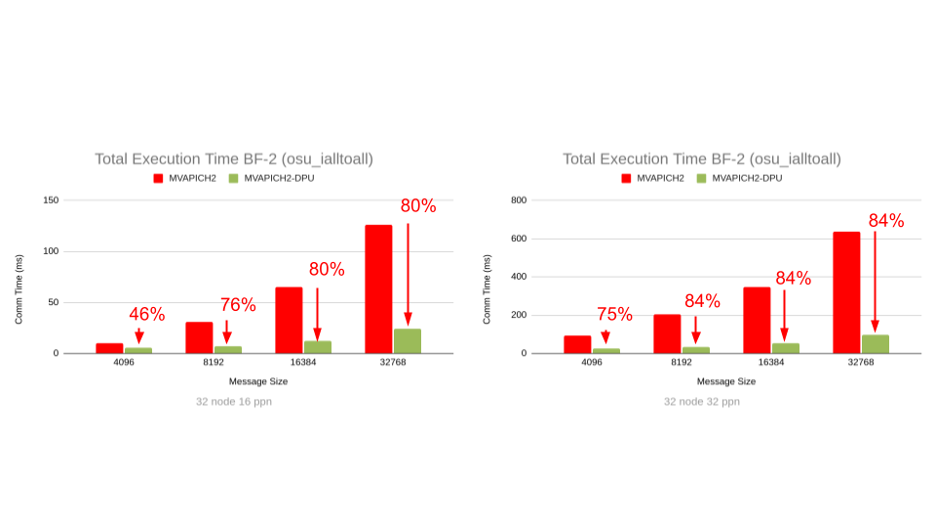 (a) Overall execution time of osu_ialltoall for small messages on Intel Xeon cluster of 32 nodes (16 ppn and 32 ppn)
(a) Overall execution time of osu_ialltoall for small messages on Intel Xeon cluster of 32 nodes (16 ppn and 32 ppn)
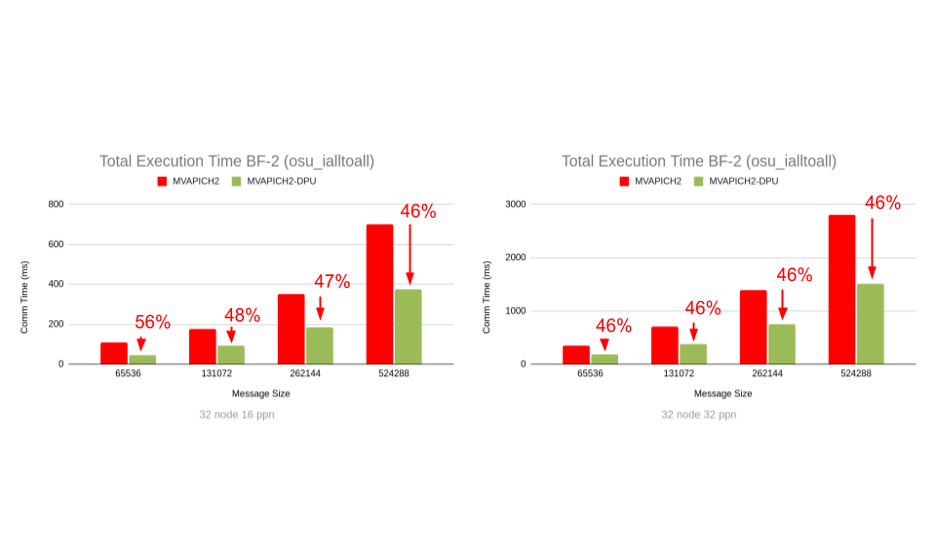 (b) Overall execution time of osu_ialltoall for large messages on Intel Xeon cluster of 32 nodes (16 ppn. and 32ppn)
(b) Overall execution time of osu_ialltoall for large messages on Intel Xeon cluster of 32 nodes (16 ppn. and 32ppn)
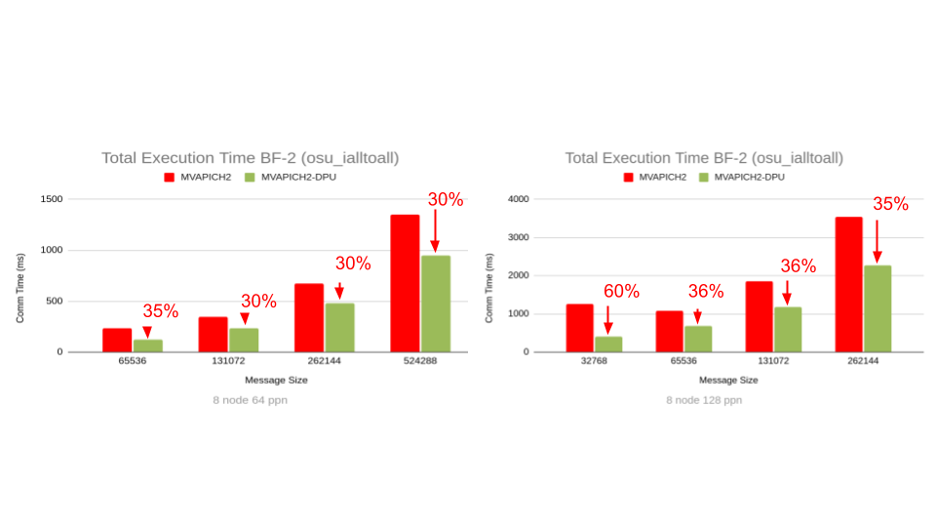 (c) Overall execution time of osu_ialltoall for large messages on AMD EPYC cluster of 8 nodes (64 ppn and 128 ppn)
(c) Overall execution time of osu_ialltoall for large messages on AMD EPYC cluster of 8 nodes (64 ppn and 128 ppn)
Figure 2: Capability of the MVAPICH2-DPU library to reduce the overall execution time of an MPI benchmark (osu_ialltoall) when computation steps are used in conjunction with the MPI_Ialltoall non-blocking collective operation in an overlapped manner.
When computation steps in an MPI application are used in conjunction with the MPI_Ialltoall nonblocking collective operation in an overlapped manner, the MVAPICH2-DPU MPI library has the unique capability to provide significant performance benefits in the overall program execution time. This is possible with the MVAPICH2-DPU MPI library because the Arm cores in the DPUs are able to implement the non-blocking alltoall operations while the Xeon/EPYC cores on the host are performing computation with peak overlap, as illustrated in Figure 1. As indicated in Figure 2, the MVAPICH2-DPU MPI library can deliver up to 84% (on Intel Xeon) and 60% (on AMD EPYC) performance benefits compared to the basic MVAPICH2 MPI library across message sizes and PPNs on a 32-node (of Intel Xeon) and an 8-node (of AMD EPYC) experiments with the OMB MPI_Ialltoall benchmark.
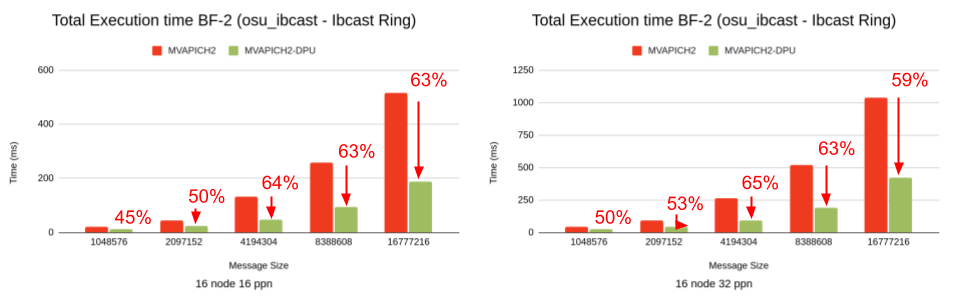
Overall execution time of osu_ibcast for messages on Intel Xeon cluster of 16 nodes (16 ppn and 32 ppn)
Figure 3: Capability of the MVAPICH2-DPU library to reduce the overall execution time of an MPI benchmark (osu_ibcast) when computation steps are used in conjunction with the MPI_Ibcast non-blocking collective operation in an overlapped manner.
When computation steps in an MPI application are used in conjunction with nonblocking collective operations such as MPI_Ialltoall and MPI_Ibcast in an overlapped manner, the MVAPICH2-DPU MPI library has the unique capability to provide significant performance benefits in the overall program execution time. This is possible with the MVAPICH2-DPU MPI library because the Arm cores in the DPUs are able to implement the non-blocking collective operations while the Xeon/EPYC cores on the host are performing computation with peak overlap, as illustrated in Figure 1 for an alltoall operation.
As indicated in Figure 2, the MVAPICH2-DPU MPI library can deliver up to 84% (on Intel Xeon) and 60% (on AMD EPYC) performance benefits compared to the basic MVAPICH2 MPI library across message sizes and PPNs on a 32-node (of Intel Xeon) and an 8-node (of AMD EPYC) experiments with the OMB MPI_Ialltoall benchmark.
As indicated in Figure 3, the MVAPICH2-DPU MPI library can deliver up to 65% (on Intel Xeon) performance benefits compared to the basic MVAPICH2 MPI library across message sizes and PPNs on a 16-node (of Intel Xeon) experiments with an MPI_Ibcast benchmark.
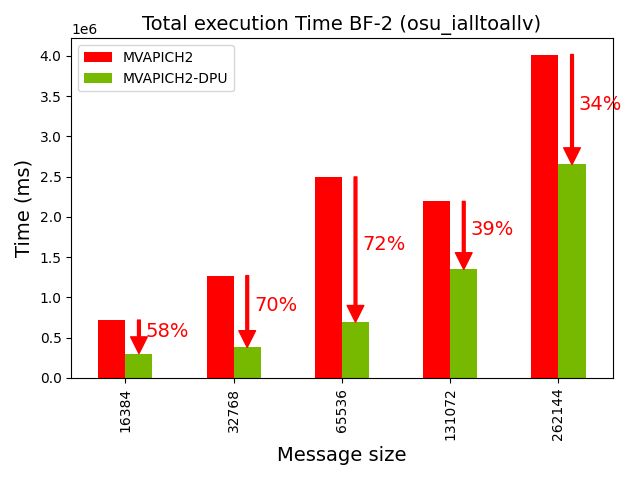
(a) Overall execution time of osu_ialltoallv for different messages on Intel Xeon cluster of 32 nodes 32 ppn (ie., 1024 processes)
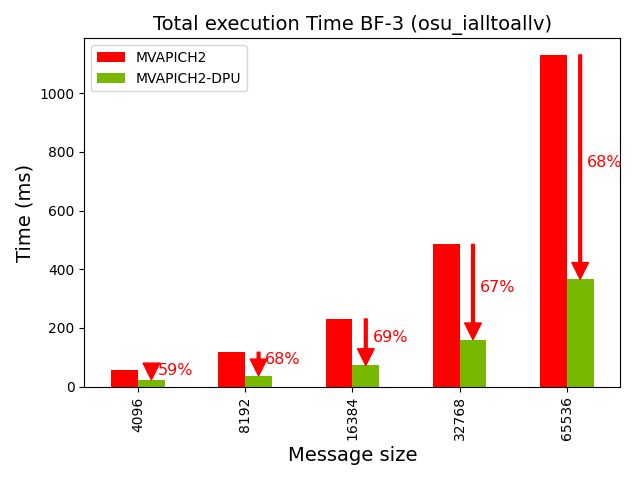
(b) Overall execution time of osu_ialltoallv for different messages on AMD EPYC cluster of 8 nodes 128 ppn (ie., 1024 processes)
Figure 4: Capability of the MVAPICH2-DPU library to reduce the overall execution time of an MPI benchmark (osu_ialltoallv) when computation steps are used in conjunction with the MPI_Ialltoallv non-blocking collective operation in an overlapped manner.
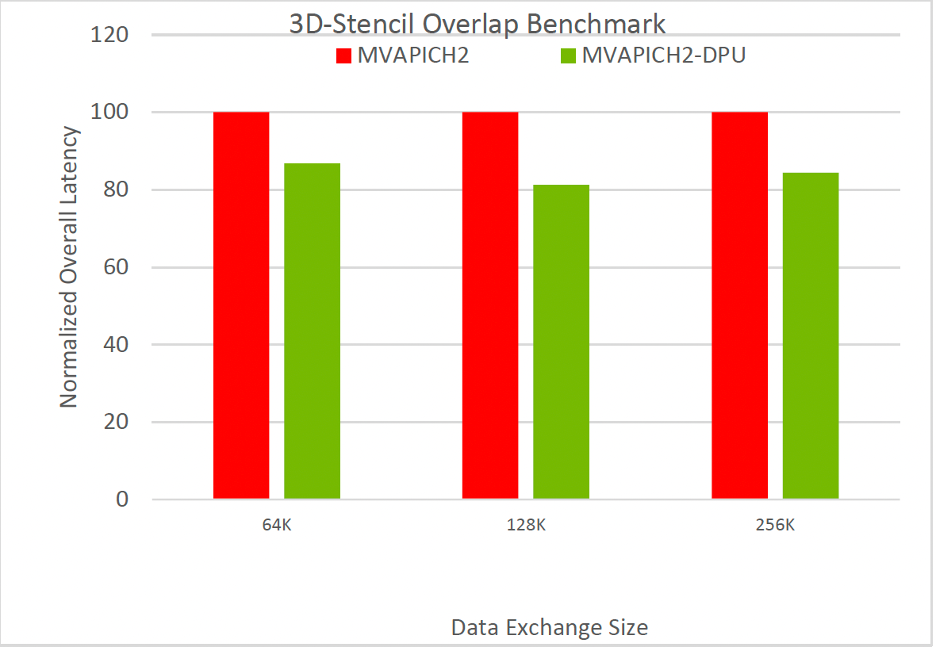 16 Nodes, 32 PPN
16 Nodes, 32 PPN
Figure 5: Capability of the MVAPICH2-DPU library to reduce the overall execution time of an MPI benchmark (3D-Stencil Overlap) when computation steps are used in conjunction with the MPI_Isend/MPI_Irecv non-blocking point-to-point operation performing data exchange with 6 neighbors (similar to 7-point 3D stencil algorithm) in an overlapped manner.
As indicated in Figure 5, the MVAPICH2-DPU MPI library can deliver up to 18% (on Intel Xeon) performance benefits compared to the basic MVAPICH2 MPI library across message sizes and 32 PPNs on a 16-node (of Intel Xeon) experiments with the 3D-Stencil overlap benchmark.
Performance Evaluation with P3DFFT Scientific Evaluation
An enhanced version of the P3DFFT MPI kernel was evaluated on the HPC-AI cluster, using 32 Xeon nodes with the MVAPICH2-DPU MPI library. As illustrated in Figure 6, the MVAPICH2-DPU MPI library reduces the overall execution time of the P3DFFT application kernel by up to 21% for various grid sizes, node counts and PPNs on Xeon nodes.
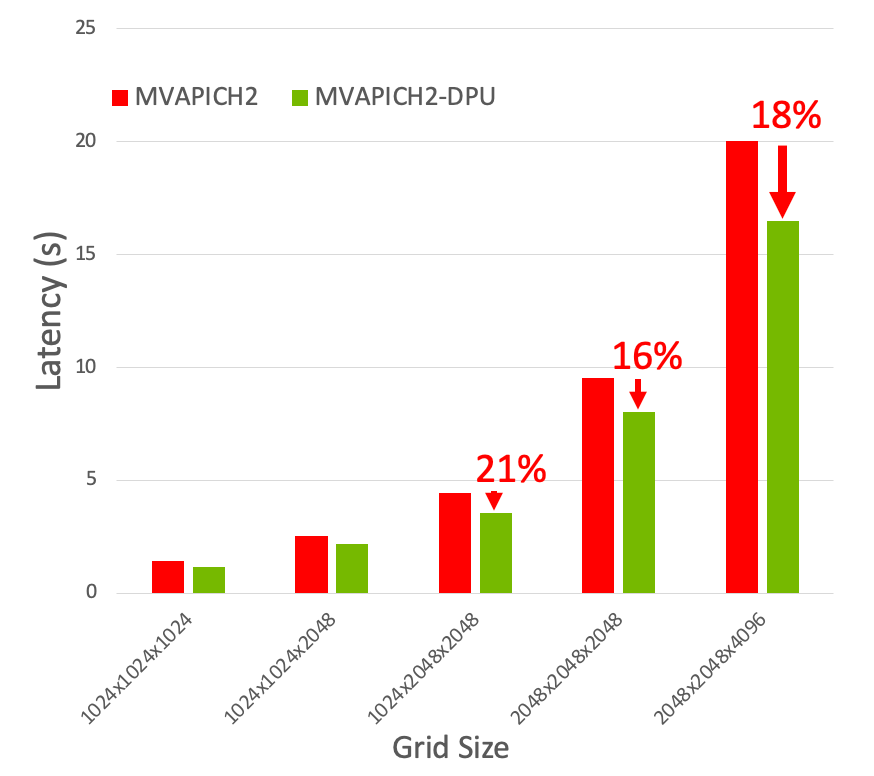 Figure 6: Capability of the MVAPICH2-DPU library to reduce overall execution time of the P3DFFT application (32 Xeon nodes 32 ppn).
Figure 6: Capability of the MVAPICH2-DPU library to reduce overall execution time of the P3DFFT application (32 Xeon nodes 32 ppn).
Performance Evaluation with High-Performance Linpack (HPL) Benchmark
An enhanced version of the High-Performance Linpack (HPL) Benchmark was evaluated on the HPC-AI cluster, using up to 16 and 31 Xeon nodes with the MVAPICH2-DPU MPI library. As illustrated in Figure 7, the DPU-offloaded version of the HPL library accelerates HPL benchmark by up to 18% while being used in conjunction with the latest MVAPICH2-DPU 2023.10 version.
Figure 7: Capability of the MVAPICH2-DPU library to accelerate HPL benchmark performance.
Performance Evaluation with Xcompact3D Scientific Application
An enhanced version of the Xcompact3D scientific application was evaluated on the HPC-AI cluster, using 8 AMD EPYC nodes with the MVAPICH2-DPU MPI library. As illustrated in Figure 8, the DPU-offloaded version of the Xcompact3D reduces the overall execution time of the Xcompact3D application by up to 10% while being used in conjunction with the MVAPICH2-DPU 2023.10 release.
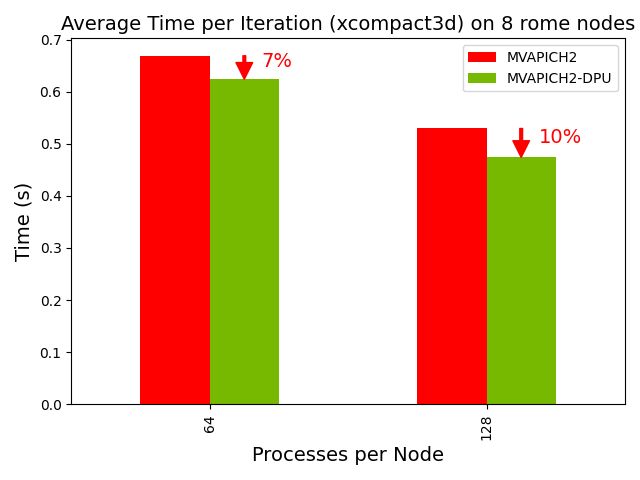
Figure 8: Capability of the MVAPICH2-DPU library to reduce the overall execution time of the Xcompact3D application on 8 AMD EPYC nodes using either 64 or 128 ppn.
Contact
Interested in a free product demo or to learn how to take advantage of the library to accelerate your HPC and AI applications? Please email us at contactus@x-scalesolutions.com for support.